반응형
3-4 정보 이용 탐색
- 상태 공간에 대한 정보를 이용해 효율을 높이는 탐색
- 휴리스틱 탐색(Heuristic Search)
언덕 오르기 방법
- 탐욕 알고리즘(Greedy Algorithm)
- 현상태를 바탕으로 연결된 이웃 상태만을 고려하므로 지역 탐색(Local Search)
- 휴리스틱을 사용
- 가장 좋은 것을 선택
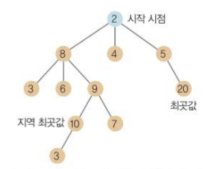
최상우선 탐색
- 언덕 오르기 방법이 최곳값을 찾아 내지 못하는 단점을 극복하고자 개발된 방법
탐색 과정
- 1단계: 시작점에서 인접한 노드 중 가장 큰 값을 선택
- 2단계: 선택된 큰 값에 인접한 노드와 앞서 선택한 노드들 중 가장 큰 값을 선택
- 3단계: 선택된 큰 값에 인접한 노드와 앞서 선택한 노드들 중 가장 큰 값을 선택
- 4단계: 선택된 큰 값에 인접한 노드와 앞서 선택한 노드들 중 가장 큰 값을 선택
- 5단계: 선택된 큰 값에 인접한 노드와 앞서 선택한 노드들 중 가장 큰 값을 선택
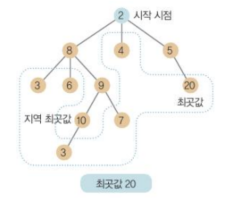
빔 탐색
- 최상우선 탐색에서 검색해야 하는 대상이 너무 많아지는 단점 극복위함
- 검색할 대상의 숫자를 제한하면 검색 대상이 늘어나는 것 조정 가능
- 빔 탐색은 w의 값에 따라 탐색의 효율이 조정되는 기법
- w가 크면 최상우선 탐색과 동일, w = 1 이면 언덕 오르기 방법과 동일
빔 탐색 과정
- 빔 탐색을 위한 w의 값을 2로 설정했을 때
- 1) 2에서 시작
- 2) 2와 연결된 3개 중 w = 2이므로 2개를 선택 (8, 5 선택)
- 3) 8에 연결된 3개 중 2개 선택 (6, 9 선택)
- 4) 5에 연결된 것은 1개이므로 20 선택
- 5) 6은 아래가 없으므로 6
- 6) 9는 10, 7 선택
- 7) 7은 아래가 없으므로 7, 10은 아래가 3이므로 3
- 모든 탐색을 마치고 최곳값 20
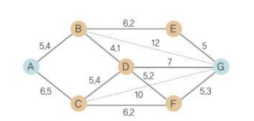
A*알고리즘
- 시작점과 끝점이 주어진 상태에서 최단 경로를 찾는 알고리즘
- 최단 경로 문제
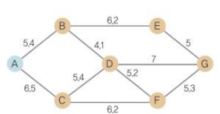
A*알고리즘의 예
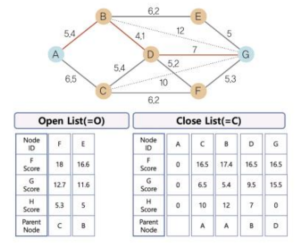
A*알고리즘의 탐색 과정
- 준비 단계: 시작점에서 목적지로 가는 최단 경로 찾기, 오픈 리스트와 클로스 리스트 준비
- 1단계: A노드에서 시작하므로 A노드의 정보를 클로즈 리스트에 추가, A노드에 연결되는 노드 정보를 오픈 리스트에 추가
- 2단계: C노드에서 시작하므로 C노드에 연결되는 노드 정보를 오픈 리스트에 추가, 오픈 리스트 중 B노드의 F값이 가장 작으므로 클로즈 리스트로 이동
- 3단계: B노드에서 시작하므로 B노드에 연결되는 노드 정보를 오픈 리스트에 추가, D 정보가 2개이므로 이 중 값이 작은 것을 채택, D노드의 F 값이 가장 작으므로 클로즈 리스트로 이동
- 4단계: D노드에서 시작하므로 D 노드에 연결되는 노드 정보를 오픈 리스트에 추가, F 노드 정보가 2개이므로 이중 값이 작은 것 채택, G 노드가 가장 값이 작으므로 클로즈 리스트로 이동
- 5단계: 최종 노드인 G가 클로즈 리스트에 있으므로 종료, 최종 경로는 G에서 시작해 Parent Node를 따라감 (G-D-B-A)
다익스트라 알고리즘
- 시작점은 있지만, 특정 목표 지점은 없고, 특정 노드까지의 최단 경로를 구할 때
- 목표 노드가 없이 원하는 특정 노드까지의 최단 거리를 구하는 데 사용
다익스트라 알고리즘 예
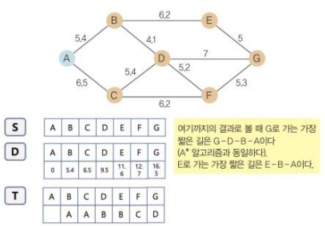
- 준비 단계: 시작점에서 다른 노드까지 가는 최단 경로를 다익스트라 알고리즘으로 찾음, 알고리즘을 수행하기 위해 S(처리가 완료된 노드의 집합), D(A~G번 노드에 대해 시작 노드로부터 소요되는 비용을 저장하는 곳), T(해당 노드로 가는 데 연결된 노드의 번호) 저장소 준비
- 1단계: 시작점을 A 노드로 하면 저장소 S에 A를 넣고,저장소 D의 A에 0을 넣는다. 저장소 T의 A는 비운다. 그 다음 저장소 D에는 A와 연결된 B. C에 A와의 거리값을 넣는다. 저장소 T에는 A와 연결되는 B. C에 A를 각각 넣는다. 여기까지의 결과로 보면 T 저장소를 참고할 때, C로 가는 가장 빠른 경로는 A를 거치는 것이다,
- 2단계: 저장소 D에 있는 A. B. C 중 A는 저장소 S에 있으므로 고려하지 않는다. 나머지 B. C 중에서 B가 값이 작으므로 저장소 S에 B를 추가한다. B 노드에 연결된 A. D, E 노드가 있다. A는 저장소 S에 있으므로 고려하지 않는다. 저장소 D에 B 노드에 연결된 D. E 노드에 B를 거쳐 가는 거리를 쓴다. 저장소 T의 D. E 노드에 B를 쓴다.
- 3단계: 저장소 D의 C, D, E 중에서 C의 값이 가장 작으므로 C를 저장소 S에 추가한다. C노드에 연결된 A, D, F 노드가 있다. A는 저장소 S에 있으므로 고려하지 않는다. 저장소 T의 D, F 노드에 C를 쓸 수 있다. 이때 D는 B와 C를 거쳐갈 수 있으므로 거리를 계산해 짧은 것을 사용한다.
- 4단계: 저장소 D에서 저장소 S에 있는 A, B, C를 뺀 나머지에서 가장 값이 작은 D를 선택한다. D 노드를 저장소 S로 이동한다. D 노드에 연결된 B, C, F, G 노드 중에서 B, C는 저장소 S에 있으므로 고려하지 않는다. 저장소 T의 F, G 노드에 D를 쓸 수 있다. 이때 F는 C, D를 거쳐갈 수 있으므로 거리를 계산해서 짧은 것을 사용한다.
- 5단계: 저장소 D에서 저장소 S에 있는 A, B, C, D를 제외한 나머지에서 가장 값이 작은 E 노드를 저장소 S로 이동한다. E노드에 연결된 B, G 노드가 있다. B 노드는 저장소 S에 있으므로 고려하지 않는다. 저장소 T의 G 노드에 D, E를 쓸 수 있다.
- 6단계: 저장소 D에서 저장소 S에 있는 A, B, C, D, E를 제외한 F, G 중에서 값이 가장 작은 F를 저장소 S로 이동한다. 저장소 T의 G노드에 연결된 D, E, F 노드 중 거리가 짧은 것을 채택한다. 저장소 D에서 마지막 남은 G를 저장소 S로 이동한다.
- 7단계: 특정 노드까지 가는 최단 경로를 확인한다.
ID3 알고리즘
- 주어진 데이터를 바탕으로 휴리스틱 방법에 따라 의사결정 트리를 제작하는 방법
- 수치 및 범주형 데이터와 대규모 데이터에서도 잘 작동함
- 엔트로피(Entropy, 평균 정보량)를 기준으로 트리를 구성하는 알고리즘
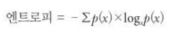
- 많은 요소들을 어떻게 고려할지에 대한 것을 체계적으로 정리한 것
ID3 알고리즘의 탐색 과정
- 1) 루트 노드 생성
- 2) 현재 트리에서 모든 단말 노드에 대해 아래 과정 반복
- 2-1) 해당 노드의 표본이 같은 클래스이면 해당 노드는 단말 노드가 되고, 해당 클래스로 레이블 부여
- 2-2) 더 이상 사용할 수 있는 속성이 없으면 수행 종료
- 2-3) 정보 획득(information gain)이 높은 속성을 선택해 노드 분해
※ 해당 내용은 <인공지능 바이블>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'인공지능(AI)' 카테고리의 다른 글
| 함수 최적화 (0) | 2023.05.20 |
|---|---|
| 탐색과 최적화 기법 (3) (0) | 2023.05.19 |
| 탐색과 최적화 기법 (1) (0) | 2023.05.17 |
| 오토마톤과 인공 생명 프로그램 (0) | 2023.05.16 |
| 지식 표현과 추론 (0) | 2023.05.15 |



