반응형
7-1 강화학습의 개념
- 시행과 보상을 바탕으로 하는 인공지능 기법
- 주어진 환경에서 의사결정을 최적화할 때 사용
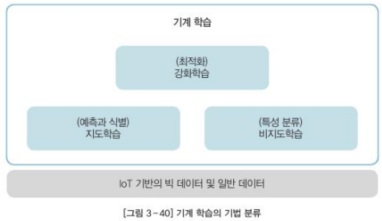
- 지도학습, 비지도학습으로 나뉨
- 지도학습: 랜덤 포레스트, 의사결정 트리, 서포트 벡터 머신 (예측과 식별)
- 비지도학습: 군집 분석, 연관 관계 분석 (특성 분류)
- 강화학습: 기계 학습의 기법 중 미래의 가치 극대화(Optimization)를 위한 방법

- 강화학습은 행동과 보상을 통해 에러를 줄여나가는 방식(Trial and Error)을 사용
- 행동의 결과가 나중에 보상으로 주어지기 때문에 좋은 행동에 대한 즉각적인 판단이 어려움(Delayed Reward)
7-2 강화학습 기법의 개념
- 마르코프 결정 과정(MDP, Markov Decision Process): 마르코프 연쇄를 바탕으로 순차적인 행동 결정 문제를 수학적으로 정의한 것
- 동적 프로그래밍의 특징 활용
- 벨만 방정식: 가치를 계산하는 방법
- 몬테카를로 근사(Monte Carlo Approximation)기법 활용
- 강화학습이 지닌 환경적 특징으로 시간차 학습(Temporal Difference Learning)
- 정책 경사법, 가치 반복법, DQN 모델

7-3 용어
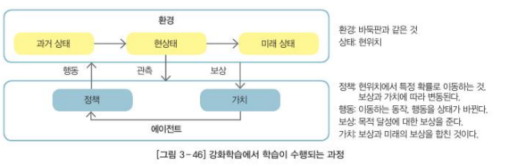
- 에이전트: 강화학습에서 행동하는 주체
- 환경: 에이전트가 존재하는 세계
- 상태: 에이전트가 갖고 있는 관찰 가능한 상태의 집합
- 행동: 에이전트가 상태에서 가능한 동작
- 보상: 환경이 에이전트에게 주는 정보
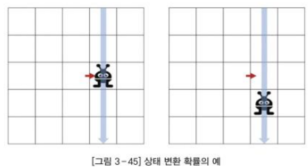
- 상태 변환 확률: 에이전트가 상태 s에서 행동 a를 취했을 때, 환경의 확률적인 요인에 의해 다른 상태에 도달할 확률
- 감가율: 에이전트가 현재에 가까운 시점에 받는 보상을 미래에 받는 보상보다 가치 있게 해 주는 개념
- 정책: 모든 상태에 대해 에이전트가 할 행동
- 보상의 종류: 즉시 보상(Immediate Reward), 지연 보상(Discounted Reward)
- 수익: 즉시 보상 외에 미래에 발생하는 지연 보상을 포함한 모든 보상의 합
- 가치: 에이전트의 상태와 정책을 고려한 상태로 저건부 수익을 계산한 것
- 강화학습은 '가치 최대화'를 통해 '수익 최대화'를 이루고, 이를 바탕으로 '많은 보상을 받을 수 있는 정책'을 확정하는 과정
7-4 강화학습 모델
- 기본 모델: 모델에서 환경의 상태와 관측이 없고, 행동과 정책을 임의로 선택하며, 보상이 있는 모델
- 정책 경사법 모델: 환경의 상태와 관측이 있고, 정책에 따라 행동하며, 보상이 있는 모델. 상태를 판단해 성공한 행동이 중요하다고 보고, 그 행동이 많이 선택되도록 정책을 갱신하는 방법
- 가치 반복법 모델: 환경의 상태와 관측이 있고, 정책에 따라 행동하며 보상이 있는 모델. 다음 상태 가치와 현상태 가치의 차이를 계산하고, 그 차이만큼 현상태의 가치를 늘리는 방법
※ 해당 내용은 <인공지능 바이블>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'인공지능(AI)' 카테고리의 다른 글
| 딥러닝 (1) (0) | 2023.05.29 |
|---|---|
| 강화 학습 (2) (0) | 2023.05.28 |
| 통계 기반 기계 학습 - 비지도 학습 (0) | 2023.05.26 |
| 통계 기반 기계 학습 - 지도학습 (0) | 2023.05.25 |
| 몬테카를로 알고리즘(Monte-Carlo Algorithm) (0) | 2023.05.24 |



