반응형
10.3 RNN을 이용한 문서 분류
10.3.3 문서의 순서정보를 활용하는 RNN 기반 문서분류
- Flatten() 대신에 SimpleRNN() 레이어를 사용
from tensorflow.keras.layers import SimpleRNN
from tensorflow.keras.optimizers import Adam
model = Sequential([
Embedding(max_words, 32),
SimpleRNN(32), # 펼쳐서 flat하게 만드는 대신 RNN 모형을 사용, maxlen만큼의 시계열 데이터
Dense(32, activation='relu'),
Dense(1, activation='sigmoid')
])
model.summary()
adam = Adam(learning_rate=1e-4)
model.compile(optimizer=adam, loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train,
epochs=10,
verbose=0,
validation_split=0.2)
plot_results(history, 'acc')
#테스트 셋으로 학습된 모형의 성능을 평가
score = model.evaluate(X_test, y_test)
print(f'#Test accuracy:{score[1]:.3f}')
"""
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 32) 320000
simple_rnn (SimpleRNN) (None, 32) 2080
dense_1 (Dense) (None, 32) 1056
dense_2 (Dense) (None, 1) 33
=================================================================
Total params: 323,169
Trainable params: 323,169
Non-trainable params: 0
_________________________________________________________________
"""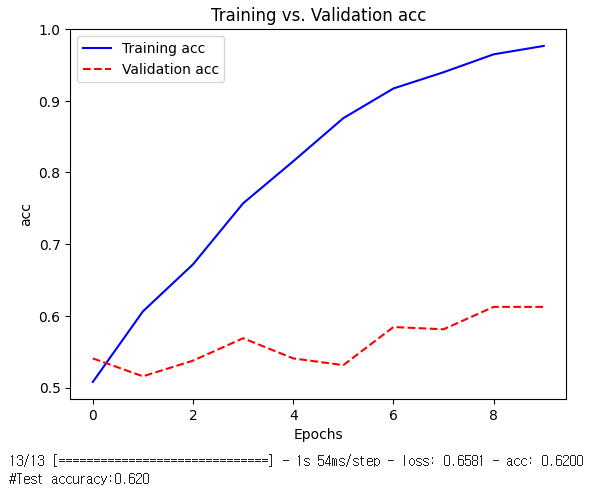
- 과대적합만 이루어지고 실제 학습이 거의 되지 않음
- 경사소실 문제로 인해 학습이 잘 되지 못하고 원하는 정보가 제대로 축적되지 못함
- 장시간에 걸친 시간의존성(long-term dependency)이 학습되지 못하는 현상
- RNN의 가장 큰 문제점
- 이를 해결하기 위해 LSTM(Long Short-Term Memory)모형이 제안됨
※ 해당 내용은 <파이썬 텍스트 마이닝 완벽 가이드>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'텍스트 마이닝' 카테고리의 다른 글
| Word2Vec, ELMo, Doc2Vec의 이해 (1) (0) | 2023.07.26 |
|---|---|
| RNN-딥러닝을 이용한 문서 분류 (6) (0) | 2023.07.25 |
| RNN-딥러닝을 이용한 문서 분류 (4) (0) | 2023.07.23 |
| RNN-딥러닝을 이용한 문서 분류 (3) (0) | 2023.07.22 |
| RNN-딥러닝을 이용한 문서 분류 (2) (0) | 2023.07.21 |


