데이터 과학과 머신 러닝(ML)은 기술 분야에서 가장 화제가 되는 주제 중 하나입니다. 먼저 데이터 과학은 통찰력을 얻기 위해 많은 양의 데이터와 처리 능력을 다루는 광범위한 학제 간 분야를 나타내고, 기계 학습은 컴퓨터 알고리즘에 엄청난 양의 데이터를 공급하여 분석을 시작하고 그 정보를 기반으로 데이터 중심의 결정을 내리는 것입니다. 오늘은 데이터 과학과 기계 학습의 차이점을 알아보고 인공지능(AI) 및 데이터 분석과 비교해 보겠습니다.
데이터 과학 vs 기계 학습
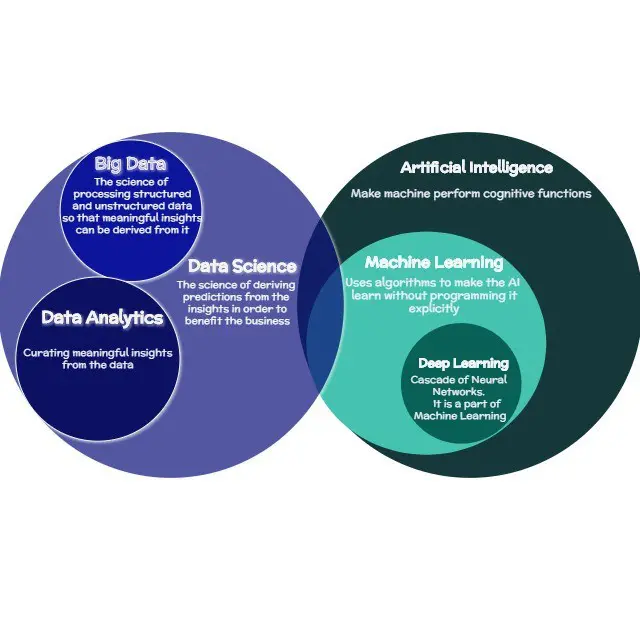
"데이터 과학과 기계 학습은 같은 것인가요?"라는 검색어는 전 세계적으로 가장 많이 검색되는 주제 중 하나입니다. 그러나 이 두 용어는 종종 함께 쓰이지만 동의어는 아닙니다.
디지털화가 빠르게 진행되는 오늘날의 세계에서는 엄청난 양의 정보가 생성됩니다. 또한, 데이터가 새로운 석유라는 표현을 사용하고 있습니다. 이는 오늘날 세계적으로 가장 가치 있는 자산 중 하나로 분류 됩니다. 따라서, 이 귀중한 자원이 사업의 장기적인 성공의 근원에 있다는 것은 놀라운 일이 아닙니다.
매일 생성되는 데이터의 양은 2.5조 바이트를 차지합니다. Statista에 따르면 2025년까지 전 세계 데이터 생성은 180 제타바이트 이상을 차지할 것이라고 합니다. 평균적으로 구글은 초당 40,000개 이상의 검색을 처리하고, 매일 35억 개의 검색을 처리합니다.
반면 머신 러닝은 컴퓨터가 풍부한 정보로부터 자율적으로 학습할 수 있도록 합니다. 세계 ML 시장의 가치는 2021년 80억 달러였으며, 2027년에는 1170억 달러를 차지할 것으로 예상됩니다. 2020년 MLaaS(서비스형 ML-as-a-Service) 시장은 16억 달러로 평가되었으며 2026년까지 121억 달러를 차지할 것으로 예상됩니다.
데이터 과학이란?
1962년, 미국의 수학자이자 통계학자인 존 투키는 오늘날 현대 데이터 과학과 유사한 분야로, 응용 수학과 통계학 분야에 대해 언급했습니다. 여기서는 데이터에서 의미 있는 정보와 통찰력을 추출하고 미래의 패턴과 행동을 예측하는 과학적 접근 방식을 도입하며, 연구 질문을 공식화하고, 정보를 수집하고, 저장하고, 분석을 위해 사전 처리하고, 분석하고, 연구 결과를 보고서와 시각화로 제시하는 방법을 연구합니다.
이 기술 분야는 ML 알고리즘, 통계적 방법, 수학적 분석과 같은 다양한 모델링 기술을 사용합니다. 즉, 정보를 처리하고, 정보를 청소하거나 청소하고, 정보의 패턴을 이해하는 것을 다룹니다. 원시, 정형 및 비정형 데이터일 수 있습니다. 데이터 정리는 데이터 세트 내에서 부정확하거나 손상되었거나 형식이 잘못되었거나 중복되거나 불완전한 데이터를 수정하거나 삭제하는 프로세스입니다.
이 분야는 금융, 전문 서비스 및 정보 기술을 포함한 두개 이상의 산업에 적용할 수 있습니다. 예를 들어, 기업은 이 분야에서 보다 현명한 비즈니스 결정을 내리고, 고객을 더 잘 이해하고, 보안을 강화하고, 기업 재무를 분석하고, 향후 시장 동향을 예측하는 데 도움이 되는 더 깊은 통찰력을 제공합니다.
데이터 과학 분야에 대해 글로벌 데이터 과학 플랫폼 시장은 2027년까지 814억 3천만 달러를 차지할 것으로 예상됩니다.
'인공지능(AI)' 카테고리의 다른 글
| 데이터 과학과 머신 러닝 (3) (0) | 2023.02.08 |
|---|---|
| 데이터 과학과 기계 학습 (2) (0) | 2023.02.07 |
| AI 기술과 인간 편향 (0) | 2023.02.05 |
| 머신 러닝 모델 관리 (2) (0) | 2023.02.04 |
| 머신 러닝 모델 관리 (1) (0) | 2023.02.03 |