반응형
3-3 함수 꾸러미, '패키지' 이해하기
패키지에는 다양한 함수들이 들어있음
ex) 그래프를 만들때 사용하는 패키지 seaborn에는 scatterplot(), barplot(), lineplot() 등 수십 가지 그래프 관련 함수가 있음
스마트폰에 앱을 깔듯 입맛대로 골라 설치 가능
패키지 활용하기
패키지 로드
import seaborn패키지 함수 사용
var = ['a', 'a', 'b', 'c']
var
##출력: ['a', 'a', 'b', 'c']seaborn.countplot(x = var)
패키지 약어 활용하기
import seaborn as sns
sns.countplot(x = var)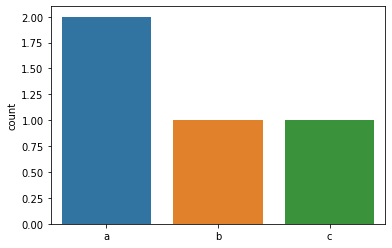
seaborn의 titanic 데이터로 그래프 만들기
seaborn의 load_dataset()으로 titanic 데이터 불러오기
함수의 다양한 기능 이용하기
df = sns.load_dataset('titanic')
df
sns.countplot(data = df, x='sex')
sns.countplot(data = df, x = 'class')
sns.countplot(data = df, x = 'class', hue = 'alive')
sns.countplot(data = df, y = 'class', hue = 'alive') # y축 class, alive별 색 표현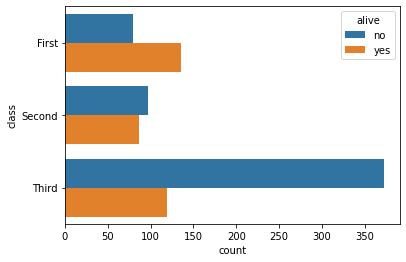
함수 사용법이 궁금할 땐 Help 함수 활용
모듈(module)
패키지 안에 있는 비슷한 함수끼리 묶어둔 것
# sklearn 패키지의 metrics 모듈 로드하기
import sklearn.metrics
# sklearn 패키지 metrics 모듈의 accuracy_score() 사용하기
#sklearn.metrics.accuracy_score()모듈명.함수명()으로 함수 사용
# sklearn 패키지의 metrics 모듈 로드하기
from sklearn import metrics
metrics.accuracy_score()함수명()으로 함수 사용
# sklearn 패키지 metrics 모듈의 accuracy_score() 로드하기
from sklearn.metrics import accuracy_score
accuracy_score()as로 약어 지정
import sklearn.metrics as met
met.accuracy_score()
from sklearn import metrics as met
met.accuracy_score()
from sklearn.metrics import accuracy_score as accuracy
accuracy()패키지 설치하기
pip install pydataset
"""
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting pydataset
Downloading pydataset-0.2.0.tar.gz (15.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 15.9/15.9 MB 34.7 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Requirement already satisfied: pandas in /usr/local/lib/python3.8/dist-packages (from pydataset) (1.3.5)
Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.8/dist-packages (from pandas->pydataset) (2.8.2)
Requirement already satisfied: numpy>=1.17.3 in /usr/local/lib/python3.8/dist-packages (from pandas->pydataset) (1.21.6)
Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.8/dist-packages (from pandas->pydataset) (2022.7.1)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.8/dist-packages (from python-dateutil>=2.7.3->pandas->pydataset) (1.15.0)
Building wheels for collected packages: pydataset
Building wheel for pydataset (setup.py) ... done
Created wheel for pydataset: filename=pydataset-0.2.0-py3-none-any.whl size=15939432 sha256=a15b0660d5b1ae233d4704ab3f5595eb5d51d63065db2cd1689218966ef05160
Stored in directory: /root/.cache/pip/wheels/d7/e5/36/85d319586b4a405d001029d489102f526ce5546248c295932a
Successfully built pydataset
Installing collected packages: pydataset
Successfully installed pydataset-0.2.0
"""패키지 함수 사용하기
import pydataset
pydataset.data()
df = pydataset.data('mtcars') # mtcars 데이터를 df에 할당
df # df 출력
반응형
혼자서 해보기
Q1 시험 점수 변수 만들고 출력하기
score = [80, 60, 70, 50, 90]
score
##출력: [80, 60, 70, 50, 90]Q2 합계 점수 구하기
sum(score)
##출력: 350Q3 합계 점수 변수 만들어 출력하기
score_total = sum(score)
score_total
##출력: 350
※ 해당 내용은 <Do it! 파이썬 데이터 분석>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'데이터 분석 학습' 카테고리의 다른 글
| 4장 데이터 프레임의 세계로 (2) (0) | 2023.04.03 |
|---|---|
| 4장 데이터 프레임의 세계로 (1) (0) | 2023.04.02 |
| 3장 데이터 분석에 필요한 연장 챙기기 (1) (0) | 2023.03.31 |
| 2장 파이썬 데이터 분석 환경 만들기 (0) | 2023.03.30 |
| 1장 안녕, 파이썬? (0) | 2023.03.30 |


