반응형
6-4 순서대로 정렬하기
df.sort_values() 이용
오름차순으로 정렬하기
exam.sort_values('math')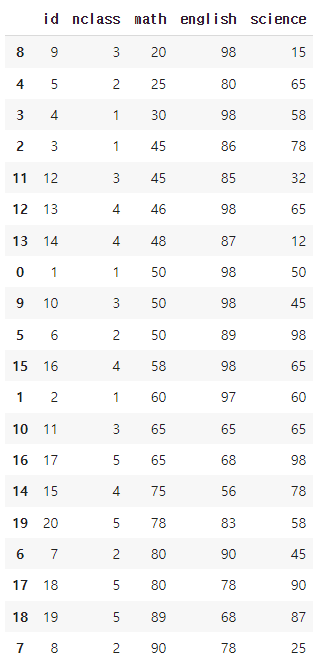
내림차순으로 정렬하기
exam.sort_values('math', ascending = False)
여러 정렬 기준 적용하기
exam.sort_values(['nclass', 'math'])
exam.sort_values(['nclass', 'math'], ascending = [True, False])
혼자서 해보기 - mpg 데이터를 이용해 분석 문제를 해결해 보세요
Q1 'audi'에서 생산한 자동차 중에 어떤 자동차 모델의 hwy(고속도로 연비)가 높은지 알아보려고 합니다. 'audi'에서 생산한 자동차 중 hwy가 1~5위에 해당하는 자동차의 데이터를 출력하세요
mpg.query('manufacturer == "audi"').sort_values('hwy', ascending = False).head(5)
6-5 파생변수 추가하기
df.assign() 를 이용해서 데이터에 파생변수를 만들어 추가 가능
파생변수 추가하기
exam.assign(total = exam['math'] + exam['english'] + exam['science'])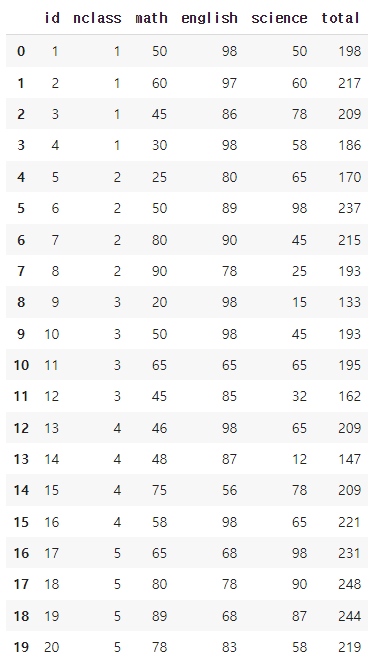
exam.assign(total = exam['math'] + exam['english'] + exam['science'],
mean = (exam['math'] + exam['english'] + exam['science']) / 3 )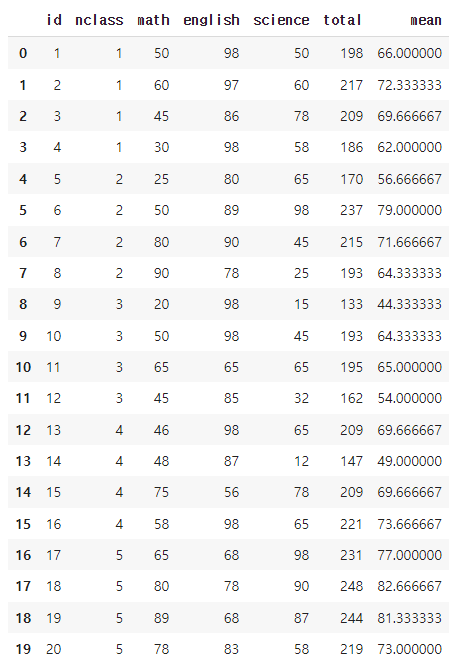
df.assign()에 np.where() 적용하기
import numpy as np
exam.assign(test = np.where(exam['science'] >= 60, 'pass', 'fail'))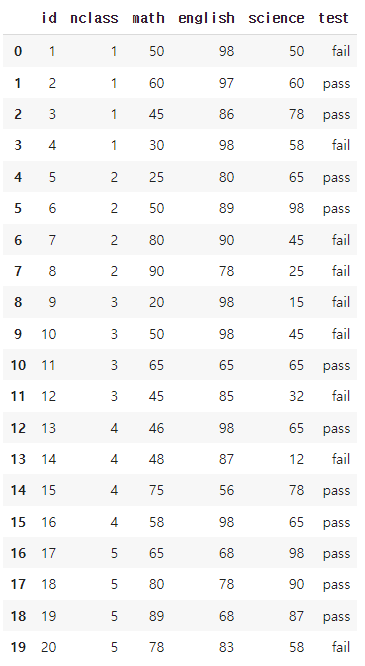
추가한 변수를 pandas 함수에 바로 활용하기
exam.assign(total = exam['math'] + exam['english'] + exam['science']).sort_values('total')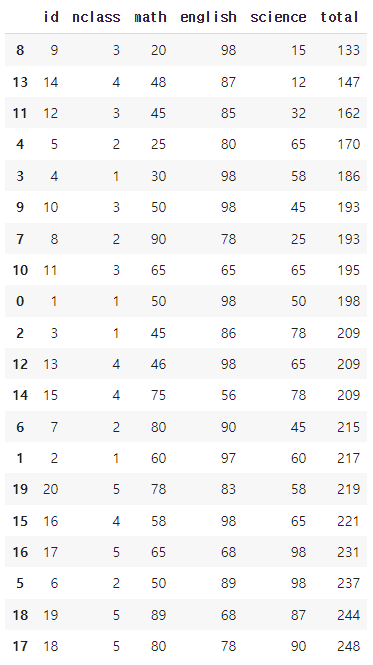
lambda 이용해 데이터 프레임명 줄여 쓰기
lambda x : 데이터 프레임명 자리에 x를 입력하겠다는 의미
long_name = pd.read_csv('exam.csv')
long_name.assign(new = long_name['math'] + long_name['english'] + long_name['science'])
long_name.assign(new = lambda x: x['math'] + x['english'] + x['science'])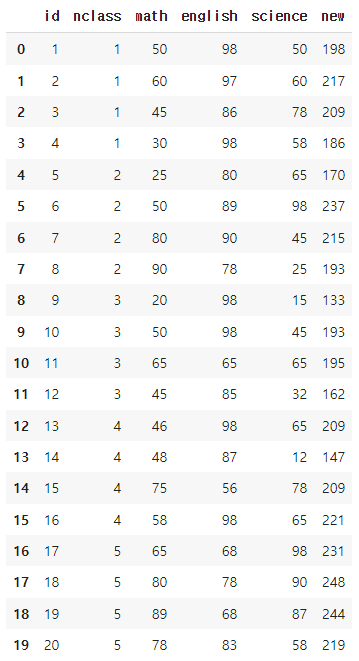
exam.assign(total = exam['math'] + exam['english'] + exam['science'],
mean = lambda x: x['total'] / 3)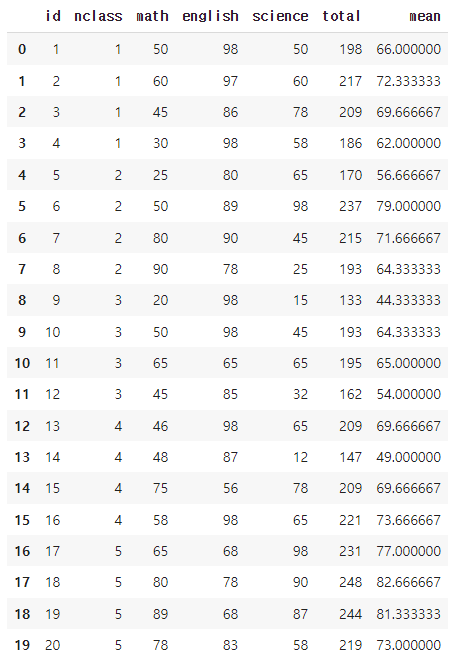
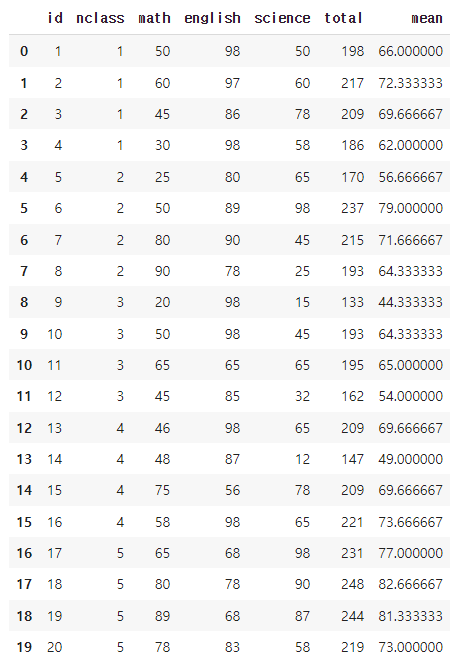
exam.assign(total = lambda x: x['math'] + x['english'] + x['science'],
mean = lambda x: x['total'] / 3)
혼자서 해보기 - mpg 데이터를 이용해 분석 문제를 해결해 보세요
Q1 mpg 데이터 복사본을 만들고, cty와 hwy를 더한 '합산 연비 변수'를 추가하세요.
mpg_copy = mpg.copy()
mpg_copy.assign(total = mpg_copy['cty'] + mpg_copy['hwy'])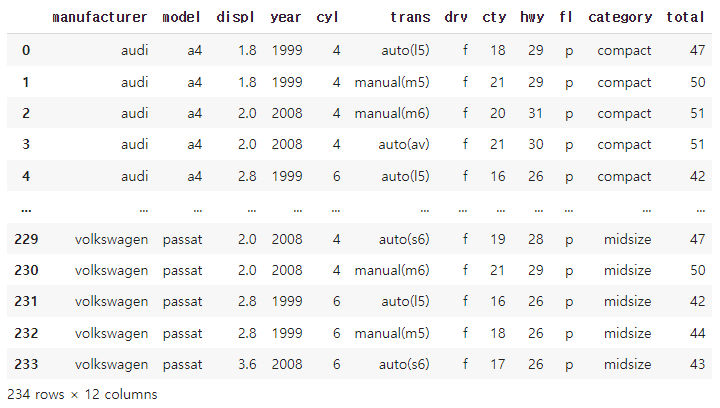
Q2 앞에서 만든 '합산 연비 변수'를 2로 나눠 '평균 연비 변수'를 추가하세요.
mpg_copy.assign(total = mpg_copy['cty'] + mpg_copy['hwy'],
mean = (mpg_copy['cty'] + mpg_copy['hwy']) / 2)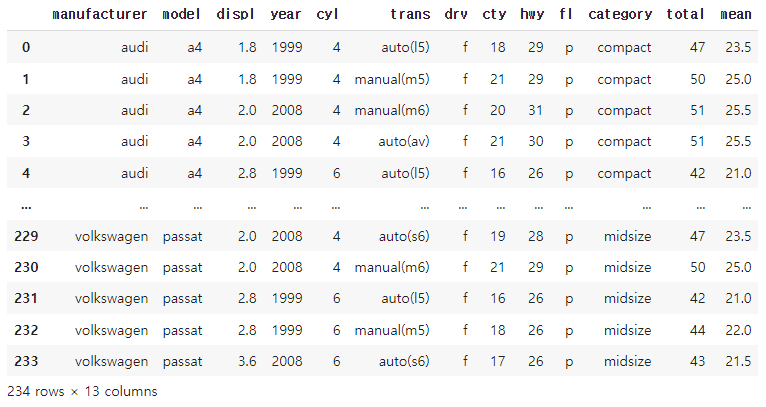
Q3 '평균 연비 변수'가 가장 높은 자동차 3종의 데이터를 출력하세요.
mpg_copy.assign(total = mpg_copy['cty'] + mpg_copy['hwy'],
mean = (mpg_copy['cty'] + mpg_copy['hwy']) / 2).sort_values('mean', ascending = False).head(3)
Q4 1~3번 문제를 해결할 수 있는 하나로 연결된 pandas 구문을 만들어 실행해 보세요. 데이터는 복사본 대신 mpg 원본을 이용하세요.
mpg.assign(total = lambda x: x['cty'] + x['hwy'],
mean = lambda x: x['total'] / 2).sort_values('mean', ascending = False).head(3)
※ 해당 내용은 <Do it! 파이썬 데이터 분석>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'데이터 분석 학습' 카테고리의 다른 글
| 6장 자유자재로 데이터 가공하기 (6) (0) | 2023.04.12 |
|---|---|
| 6장 자유자재로 데이터 가공하기 (5) (0) | 2023.04.11 |
| 6장 자유자재로 데이터 가공하기 (3) (0) | 2023.04.09 |
| 6장 자유자재로 데이터 가공하기 (2) (0) | 2023.04.08 |
| 6장 자유자재로 데이터 가공하기 (1) (0) | 2023.04.07 |



