반응형
6-3 필요한 변수만 추출하기
변수 추출하기
데이터 프레임명 뒤에 []를 입력한 다음 추출한 변수명을 따옴표로 감싸서 입력
exam['math']
"""
0 50
1 60
2 45
3 30
4 25
5 50
6 80
7 90
8 20
9 50
10 65
11 45
12 46
13 48
14 75
15 58
16 65
17 80
18 89
19 78
Name: math, dtype: int64
"""exam['english']
"""
0 98
1 97
2 86
3 98
4 80
5 89
6 90
7 78
8 98
9 98
10 65
11 85
12 98
13 87
14 56
15 98
16 68
17 78
18 68
19 83
Name: english, dtype: int64
"""exam[['nclass', 'math', 'english']]
변수 제거하기
df.drop()을 이용
exam.drop(columns = 'math')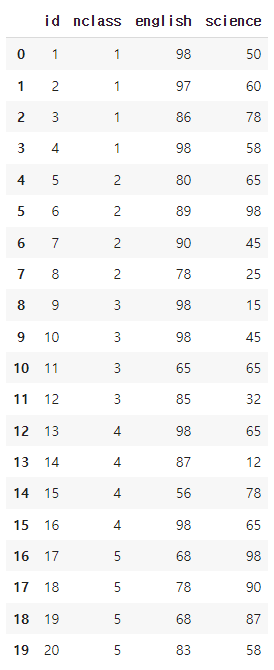
exam.drop(columns = ['math', 'english'])
pandas 함수 조합하기
query()와 []조합하기
exam.query('nclass == 1')['english']
"""
0 98
1 97
2 86
3 98
Name: english, dtype: int64
"""exam.query('math >= 50')[['id', 'math']]
일부만 출력하기
exam.query('math >= 50')[['id', 'math']].head()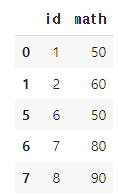
exam.query('math >= 50')[['id', 'math']].head(10)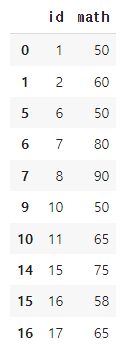
가독성 있게 코드 줄 바꾸기
exam.query('math >= 50')\
[['id', 'math']]\
.head(10)
혼자서 해보기 - mpg 데이터를 이용해 분석 문제를 해결해 보세요
Q1 mpg 데이터는 11개 변수로 구성됩니다. 이 중 일부만 추출해 분석에 활용하려고 합니다. mpg 데이터에서 category(자동차 종류), cty(도시 연비) 변수를 추출해 새로운 데이터를 만드세요. 새로 만든 데이터의 일부를 출력해 두 변수로만 구성되어 있는지 확인하세요.
mpg = pd.read_csv('mpg.csv')
mpg_p = mpg[['category', 'cty']]
mpg_p.head()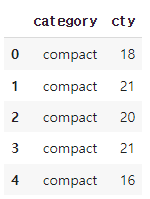
Q2 자동차 종류에 따라 도시 연비가 어떻게 다른지 알아보려고 합니다. 앞에서 추출한 데이터를 이용해 category(자동차 종류)가 'suv'인 자동차와 'compact'인 자동차 중 어떤 자동차의 cty(도시 연비) 평균이 더 높은지 알아보세요.
mpg_p.query('category == "suv"')['cty'].mean()
##출력: 13.5
mpg_p.query('category == "compact"')['cty'].mean()
##출력: 20.127659574468087
※ 해당 내용은 <Do it! 파이썬 데이터 분석>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'데이터 분석 학습' 카테고리의 다른 글
| 6장 자유자재로 데이터 가공하기 (5) (0) | 2023.04.11 |
|---|---|
| 6장 자유자재로 데이터 가공하기 (4) (0) | 2023.04.10 |
| 6장 자유자재로 데이터 가공하기 (2) (0) | 2023.04.08 |
| 6장 자유자재로 데이터 가공하기 (1) (0) | 2023.04.07 |
| 5장 데이터 분석 기초! - 데이터 파악하기, 다루기 쉽게 수정하기 (3) (0) | 2023.04.06 |



