반응형
7-1 빠진 데이터를 찾아라! - 결측치 정제하기
결측치(missing value) ckwrl
결측치 만들기: NumPy 패키지의 np.nan 입력
import pandas as pd
import numpy as np
df = pd.DataFrame({'sex' : ['M', 'F', np.nan, 'M', 'F'],
'score' : [5,4,3,4, np.nan]})
df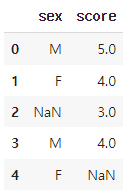
df['score'] + 1
"""
0 6.0
1 5.0
2 4.0
3 5.0
4 NaN
Name: score, dtype: float64
"""결측치 확인하기: pd.isna()에 df를 입력하면 결측치는 True, 결측치가 아닌 값은 False
pd.isna(df)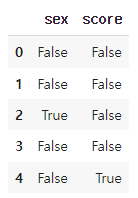
결측치 제거하기
df.dropna()를 이용하면 결측치가 있는 행 제거 가능 subset에 []를 이용해 변수명 입력
결측치 있는 행 제거
df.dropna(subset = ['score'])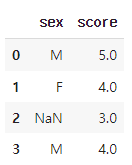
df_nomiss = df.dropna(subset = ['score'])
df_nomiss['score'] + 1
"""
0 6.0
1 5.0
2 4.0
3 5.0
Name: score, dtype: float64
"""여러 변수에 결측치 없는 데이터 추출
df_nomiss = df.dropna(subset = ['score', 'sex'])
df_nomiss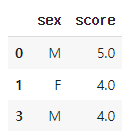
결측치가 하나라도 있으면 제거
df_nomiss2 = df.dropna()
df_nomiss2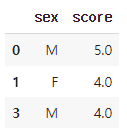
결측치 제거하지 않고 분석하기: 편리하지만 결측치가 있는지 모른 채로 데이터를 다루게 된다는 위험 있음
df['score'].mean()
##출력: 4.0
df['score'].sum()
##출력: 16.0df.groupby('sex').agg(mean_score = ('score', 'mean'),
sum_score = ('score', 'sum'))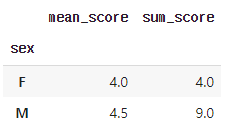
결측치 대체하기
결측치 대체법(imputation)
평균값으로 결측치 대체하기
exam = pd.read_csv('exam.csv')
exam.loc[[2, 7, 14], ['math']] = np.nan
exam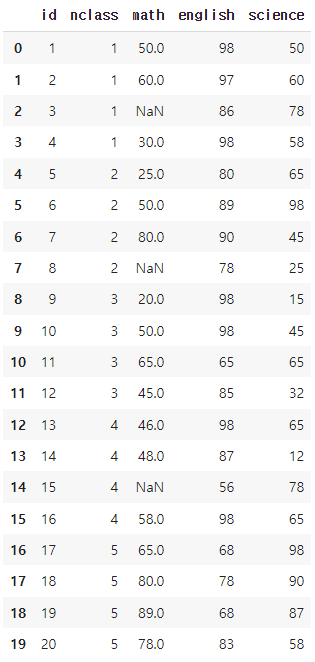
exam['math'].mean()
##출력: 55.23529411764706exam['math'] = exam['math'].fillna(55)
exam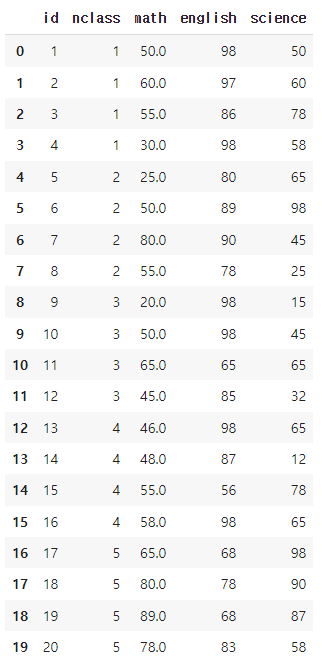
exam['math'].isna().sum()
##출력: 0
혼자서 해보기 - 결측치가 들어 있는 mpg 데이터를 이용해 분석 문제를 해결해 보세요.
mpg = pd.read_csv('mpg.csv')
mpg.loc[[64, 123, 130, 152, 211], "hwy"] = np.nanQ1 drv(구동 방식)별로 hwy(고속도로 연비) 평균이 어떻게 다른지 알아보려고 합니다. 분석을 하기 전에 우선 두 변수에 결측치가 있는지 확인해야 합니다. drv 변수와 hwy 변수에 결측치가 몇 개 있는지 알아보세요.
mpg[['drv', 'hwy']].isna().sum()
"""
drv 0
hwy 5
dtype: int64
"""Q2 df.dropna()를 이용해 hwy 변수의 결측치를 제거하고, 어떤 구동 방식의 hwy 평균이 높은지 알아보세요. 하나의 pandas 구문으로 만들어야 합니다.
mpg.dropna(subset = ['hwy']).groupby('drv').agg(mean_hwy = ('hwy', 'mean'))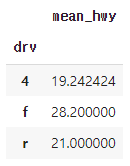
※ 해당 내용은 <Do it! 파이썬 데이터 분석>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'데이터 분석 학습' 카테고리의 다른 글
| 7장 데이터 정제 - 빠진 데이터, 이상한 데이터 제거하기 (3) (0) | 2023.04.16 |
|---|---|
| 7장 데이터 정제 - 빠진 데이터, 이상한 데이터 제거하기 (2) (0) | 2023.04.15 |
| 6장 자유자재로 데이터 가공하기 (7) (0) | 2023.04.13 |
| 6장 자유자재로 데이터 가공하기 (6) (0) | 2023.04.12 |
| 6장 자유자재로 데이터 가공하기 (5) (0) | 2023.04.11 |



