반응형
7-2 이상한 데이터를 찾아라! - 이상치 정제하기
이상치 제거하기-극단적인 값
극단치(outlier)
상자 그림(box plot)으로 극단치 기준 정하기
1. 상자 그림 살펴보기
mpg = pd.read_csv('mpg.csv')
import seaborn as sns
sns.boxplot(data = mpg, y = 'hwy')
2. 극단치 기준값 구하기
1) 1사분위수, 3사분위수 구하기
pct25 = mpg['hwy'].quantile(.25)
pct25
##출력: 18.0
pct75 = mpg['hwy'].quantile(.75)
pct75
##출력: 27.02) IQR(inter quartile range, 사분위 범위) 구하기
iqr = pct75 - pct25
iqr
##출력: 9.03) 하한, 상한 구하기
pct25 - 1.5 * iqr # 하한
##출력: 4.5
pct75 + 1.5 * iqr # 상한
##출력: 40.53. 극단치를 결측 처리하기
# 4.5 ~ 40.5 벗어나면 NaN 부여
mpg['hwy'] = np.where((mpg['hwy'] < 4.5) | (mpg['hwy'] > 40.5), np.nan, mpg['hwy'])
# 결측치 빈도 확인
mpg['hwy'].isna().sum()
##출력: 34. 결측치 제거하고 분석하기
# hwy 결측치 제거
# drv별 분리
# hwy 평균 구하기
mpg.dropna(subset = ['hwy']) \
.groupby('drv') \
.agg(mean_hwy = ('hwy', 'mean'))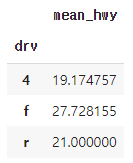
혼자서 해보기 - 이상치가 들어 있는 mpg 데이터를 활용해 분석 문제를 해결해 보세요.
mpg = pd.read_csv('mpg.csv')
mpg.loc[[9, 13, 57, 92], 'drv'] = 'k'
mpg.loc[[28, 42, 128, 202], 'cty'] = [3, 4, 39, 42]Q1 drv에 이상치가 있는지 확인하세요. 이상치를 결측 처리한 다음 이상치가 사라졌는지 확인하세요. 결측 처리를 할 때는 df.isin()을 활용하세요.
mpg['drv'].value_counts(sort = False)
"""
mpg['drv'].value_counts(sort = False)
f 106
4 100
k 4
r 24
Name: drv, dtype: int64
"""mpg['drv'] = np.where(mpg['drv'].isin(['4', 'f', 'r']), mpg['drv'], np.nan)
mpg['drv'].value_counts().sort_index()
"""
4 100
f 106
r 24
Name: drv, dtype: int64
"""Q2 상자 그림을 이용해 cty에 이상치가 있는지 확인하세요. 상자 그림 기준으로 정상 범위를 벗어난 값을 결측 처리한 다음 다시 상자 그림을 만들어 이상치가 사라졌는지 확인하세요.
sns.boxplot(data = mpg, y = 'cty')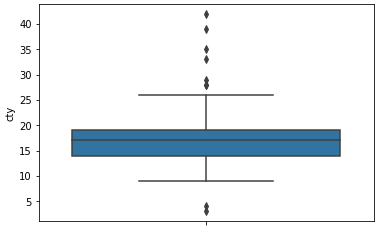
pct25 = mpg['cty'].quantile(.25) # 1사분위수
pct75 = mpg['cty'].quantile(.75) # 3사분위수
iqr = pct75 - pct25pct25 - 1.5 * iqr
##출력: 6.5
pct75 + 1.5 * iqr
##출력: 26.5mpg['cty'] = np.where((mpg['cty'] < 6.5) | (mpg['cty'] > 26.5), np.nan, mpg['cty'])
sns.boxplot(data = mpg, y ='cty')
Q3 두 변수의 이상치를 결측 처리했으니 이제 분석할 차례입니다. 이상치를 제거한 다음 drv별로 cty 평균이 어떻게 다른지 알아보세요. 하나의 pandas 구문으로 만들어야 합니다.
mpg.dropna(subset = ['drv', 'cty']).groupby('drv').agg(mean_cty = ('cty', 'mean'))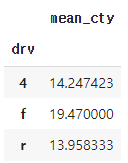
정리하기
## 1. 결측치 정제하기
pd.isna(df).sum() # 결측치 확인
df_nomiss = df.dropna(subset = ['score']) # 결측치 제거
df_nomiss = df.dropna(subset = ['score', 'sex']) # 여러 변수 동시에 결측치 제거
## 2. 이상치 정제하기
# 이상치 확인
df['sex'].value_counts(sort = False)
# 이상치 결측 처리
df['sex'] = np.where(df['sex'] == 3, np.nan, df['sex'])
# 상자 그림으로 극단치 기준값 찾기
pct25 = mpg['hwy'].quantile(.25) # 1사분위수
pct75 = mpg['hwy'].quantile(.75) # 3사분위수
iqr = pct75 - pct25 # IQR
pct25 - 1.5 * iqr # 하한
pct75 + 1.5 * iqr # 상한
# 극단치 결측 처리
mpg['hwy'] = np.where((mpg['hwy'] < 4.5) | (mpg['hwy'] > 40.5), np.nan, mpg['hwy'])
※ 해당 내용은 <Do it! 파이썬 데이터 분석>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'데이터 분석 학습' 카테고리의 다른 글
| 8장 그래프 만들기 (2) (0) | 2023.04.18 |
|---|---|
| 8장 그래프 만들기 (1) (0) | 2023.04.17 |
| 7장 데이터 정제 - 빠진 데이터, 이상한 데이터 제거하기 (2) (0) | 2023.04.15 |
| 7장 데이터 정제 - 빠진 데이터, 이상한 데이터 제거하기 (1) (0) | 2023.04.14 |
| 6장 자유자재로 데이터 가공하기 (7) (0) | 2023.04.13 |



