반응형
14-3 상관분석 - 두 변수의 관계 분석하기
- 상관분석(correlation analysis): 두 연속 변수가 서로 관련이 있는지 검정하는 통계 분석 기법
실업자 수와 개인 소비 지출의 상관관계
1. 상관계수 구하기
2. 유의확률 구하기
# economics 데이터 불러오기
economics = pd.read_csv('economics.csv')
# 상관행렬 만들기
economics[['unemploy', 'pce']].corr()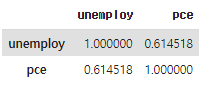
# 상관분석
stats.pearsonr(economics['unemploy'], economics['pce'])
##출력: PearsonRResult(statistic=0.614517614193208, pvalue=6.773527303289964e-61)상관행렬 히트맵 만들기
1. 상관행렬 만들기
2. 히트맵 만들기
3. 대각 행렬 제거하기
- (1) mask 만들기
- (2) 히트맵에 mask 적용하기
- (3) 빈 행과 열 제거하기
mtcars = pd.read_csv('mtcars.csv')
mtcars.head()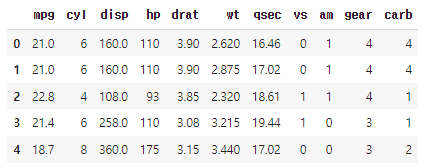
car_cor = mtcars.corr() # 상관행렬 만들기
car_cor = round(car_cor, 2) # 소수점 둘째 자리까지 반올림
car_cor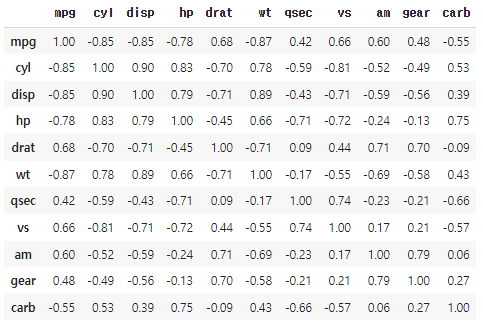
import matplotlib.pyplot as plt
plt.rcParams.update({'figure.dpi' : '120', # 해상도 설정
'figure.figsize': [7.5, 5.5]}) # 가로 세로 크기 설정
# 히트맵 만들기
import seaborn as sns
sns.heatmap(car_cor,
annot = True, # 상관계수 표시
cmap = 'RdBu') # 컬러맵
# mask 만들기
import numpy as np
mask = np.zeros_like(car_cor)
mask
"""
array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
"""# 오른쪽 위 대각 행렬을 1로 바꾸기
mask[np.triu_indices_from(mask)] = 1
mask
"""
array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
[0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1.],
[0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1.],
[0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1.],
[0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1.],
[0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])
"""# 히트맵 만들기
sns.heatmap(data = car_cor,
annot = True, # 상관계수 표시
cmap = 'RdBu', # 컬러맵
mask = mask) # mask 적용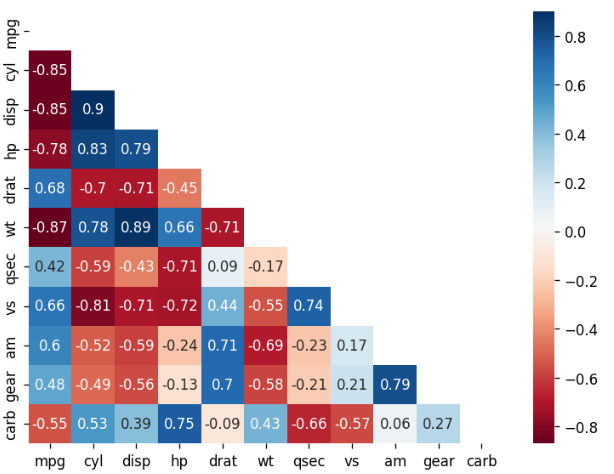
mask_new = mask[1:, :-1] # mask 첫 번째 행, 마지막 열 제거
cor_new = car_cor.iloc[1:, :-1] # 상관행렬 첫 번째 행, 마지막 열 제거
# 히트맵 만들기
sns.heatmap(data = cor_new,
annot = True, # 상관계수 표시
cmap = 'RdBu', # 컬러맵
mask = mask_new) # mask 적용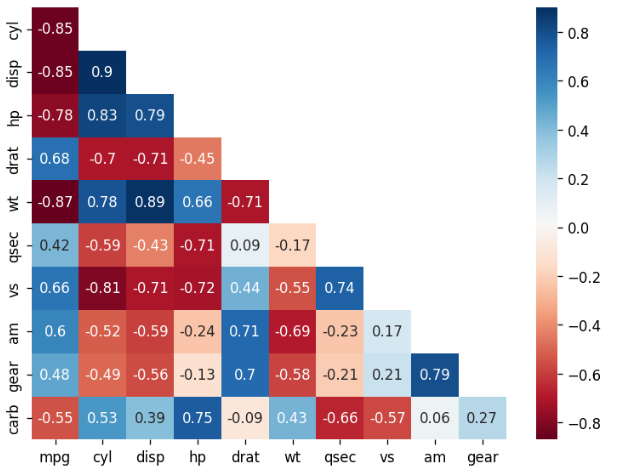
# 히트맵 만들기
sns.heatmap(data = cor_new,
annot = True, # 상관계수 표시
cmap = 'RdBu', # 컬러맵
mask = mask_new, # mask 적용
linewidths = .5, # 경계 구분선 추가
vmax = 1, # 가장 진한 파란색으로 표현할 최대값
vmin = -1, # 가장 진한 빨간색으로 표현할 최소값
cbar_kws = {'shrink': .5}) # 범례 크기 줄이기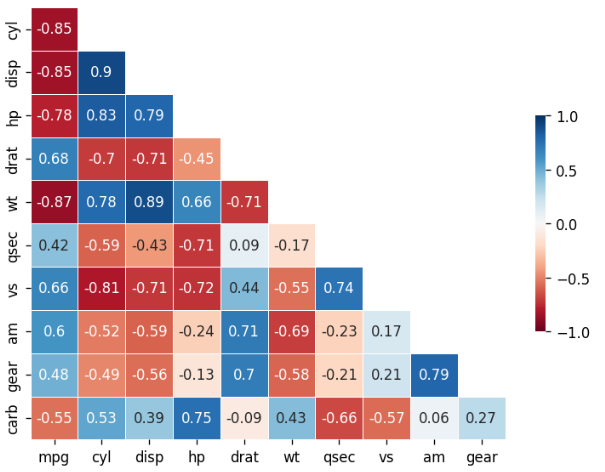
※ 해당 내용은 <Do it! 파이썬 데이터 분석>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'데이터 분석 학습' 카테고리의 다른 글
| 15장 머신러닝을 이용한 예측 분석 (2) (0) | 2023.05.09 |
|---|---|
| 15장 머신러닝을 이용한 예측 분석 (1) (0) | 2023.05.08 |
| 14장 통계 분석 기법을 이용한 가설 검정 (1) (0) | 2023.05.06 |
| 12장 인터랙티브 그래프 (0) | 2023.05.05 |
| 11장 지도 시각화 (2) (0) | 2023.05.04 |



