반응형
16.1 다중 언어 BERT 사전학습 모형의 미세조정학습
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
df = pd.read_csv('/content/daum_movie_review.csv')
# rating이 6보다 작으면 0 즉 부정, 6 이상이면 긍정으로 라벨 생성
y = [0 if rate < 6 else 1 for rate in df.rating]
# 데이터셋을 학습, 검증, 평가의 세 데이터셋으로 분리
X_train_val, X_test, y_train_val, y_test = train_test_split(df.review.tolist(), y, random_state=0)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, random_state=0)
print('#Train set size:', len(X_train))
print('#Validation set size:', len(X_val))
print('#Test set size:', len(X_test))
"""
#Train set size: 8282
#Validation set size: 2761
#Test set size: 3682
"""import torch
from datasets import load_metric
metric = load_metric("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
class OurDataset(torch.utils.data.Dataset):
def __init__(self, inputs, labels):
self.inputs = inputs
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.inputs.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
print(tokenizer.tokenize("안녕하세요. 반갑습니다."))
inputs = tokenizer("안녕하세요. 반갑습니다.")
print(inputs)
"""
['안', '##녕', '##하', '##세', '##요', '.', '반', '##갑', '##습', '##니다', '.']
{'input_ids': [101, 9521, 118741, 35506, 24982, 48549, 119, 9321, 118610, 119081, 48345, 119, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
"""from transformers import BertForSequenceClassification
from transformers import Trainer, TrainingArguments
# 토큰화
train_input = tokenizer(X_train, truncation=True, padding=True, return_tensors="pt")
val_input = tokenizer(X_val, truncation=True, padding=True, return_tensors="pt")
test_input = tokenizer(X_test, truncation=True, padding=True, return_tensors="pt")
# Dataset 생성
train_dataset = OurDataset(train_input, y_train)
val_dataset = OurDataset(val_input, y_val)
test_dataset = OurDataset(test_input, y_test)
# bert-base-multilingual-cased 사전학습모형으로부터 분류기 모형을 생성
model = BertForSequenceClassification.from_pretrained("bert-base-multilingual-cased")
# Trainer에서 사용할 하이퍼 파라미터 지정
training_args = TrainingArguments(
output_dir='./results', # 모형 예측이나 체크포인트 출력 폴더, 반드시 필요함
num_train_epochs=2, # 학습 에포크 수
evaluation_strategy="steps", # epoch마다 검증 데이터셋에 대한 평가 지표를 출력
eval_steps = 500, #
per_device_train_batch_size=8, # 학습에 사용할 배치 사이즈
per_device_eval_batch_size=16, # 평가에 사용할 배치 사이즈
warmup_steps=200, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
)
# Trainer 객체 생성
trainer = Trainer(
model=model, # 학습할 모형
args=training_args, # 위에서 정의한 학습 매개변수
train_dataset=train_dataset, # 훈련 데이터셋
eval_dataset=val_dataset, # 검증 데이터셋
compute_metrics=compute_metrics,
)
# 미세조정학습 실행
trainer.train()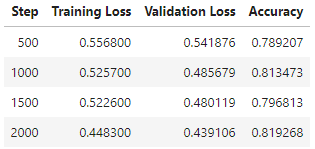
trainer.save_model("my_model")
trainer.evaluate(eval_dataset=test_dataset)
"""
{'eval_loss': 0.45343217253685,
'eval_accuracy': 0.8009234111895709,
'eval_runtime': 37.1026,
'eval_samples_per_second': 99.238,
'eval_steps_per_second': 6.226,
'epoch': 2.0}
"""
※ 해당 내용은 <파이썬 텍스트 마이닝 완벽 가이드>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'텍스트 마이닝' 카테고리의 다른 글
| 한국어 문서에 대한 BERT 활용 (2) (0) | 2023.08.06 |
|---|---|
| BERT 사전학습 모형에 대한 미세조정학습 (3) (0) | 2023.08.04 |
| BERT 사전학습 모형에 대한 미세조정학습 (2) (0) | 2023.08.03 |
| BERT 사전학습 모형에 대한 미세조정학습 (1) (0) | 2023.08.02 |
| BERT의 이해와 간단한 활용 (2) (0) | 2023.08.01 |
