반응형
5-2 변수명 바꾸기
변수명 바꾸기
1. 데이터 프레임 만들기
df_raw = pd.DataFrame({'var1' : [1,2,1],
'var2' : [2,3,2]})
df_raw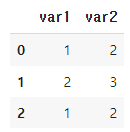
2. 데이터 프레임 복사본 만들기
df_new = df_raw.copy()
df_new
3. 변수명 바꾸기
df_new = df_new.rename(columns = {'var2':'v2'})
df_new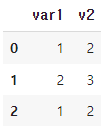
혼자서 해보기
Q1 mpg 데이터를 불러와 복사본 만들기
mpg = pd.read_csv('mpg.csv')
mpg_copy = mpg.copy()
mpg_copy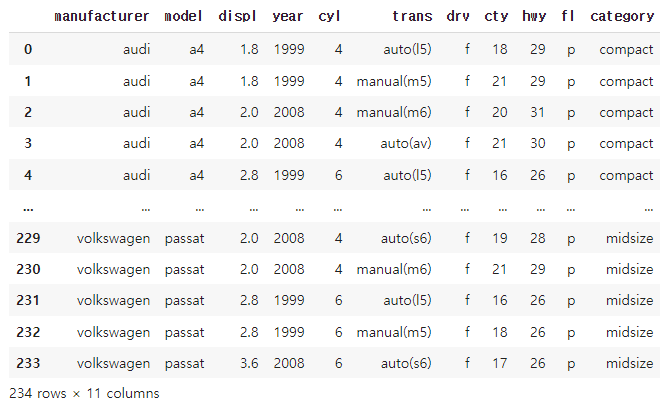
Q2 복사본 데이터를 이용해 cty는 city로, hwy는 highway로 수정
mpg_copy = mpg_copy.rename(columns = {'cty' : 'city'})
mpg_copy = mpg_copy.rename(columns = {'hwy' : 'highway'})
mpg_copy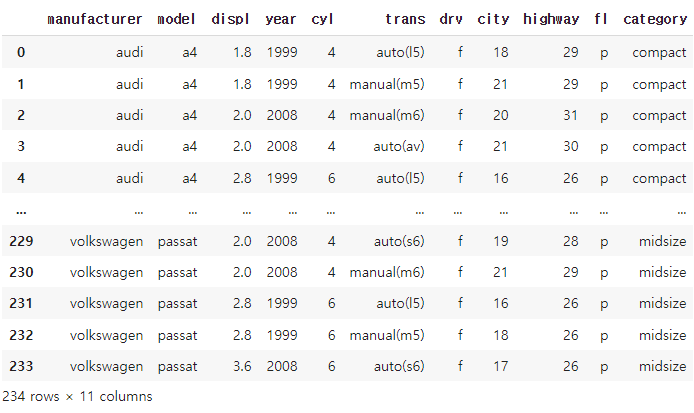
Q3 데이터 일부 출력
mpg_copy
5-3 파생변수 만들기
파생변수(dervied variable) : 기존의 변수를 변형해 만든 변수
변수 조합해 파생변수 만들기
1. 변수 2개로 구성된 데이터 프레임 만들기
df = pd.DataFrame({'var1' : [4,3,8],
'var2' : [2,6,1]})
df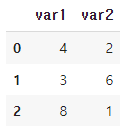
2. var_sum 파생변수 만들어 추가
df['var_sum'] = df['var1'] + df['var2']
df
3. var_mean 파생변수 만들어 추가
df['var_mean'] = (df['var1'] + df['var2']) / 2
df
mpg 통합 연비 변수 만들기
mpg['total'] = (mpg['cty'] + mpg['hwy']) / 2
mpg.head()
sum(mpg['total']) / len(mpg)
##출력: 20.14957264957265mpg['total'].mean()
##출력: 20.14957264957265조건문을 활용해 파생변수 만들기
1. 기준값 정하기
2. 합격 판정 변수 만들기
3. 빈도표로 합격 판정 자동차 수 살펴보기
4. 막대 그래프로 빈도 표현하기
mpg['total'].describe()
"""
count 234.000000
mean 20.149573
std 5.050290
min 10.500000
25% 15.500000
50% 20.500000
75% 23.500000
max 39.500000
Name: total, dtype: float64
"""mpg['total'].plot.hist()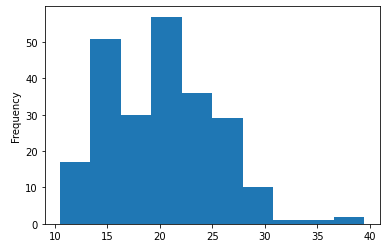
import numpy as np
mpg['test'] = np.where(mpg['total'] >= 20, 'pass', 'fail')
mpg.head()

mpg['test'].value_counts()
"""
pass 128
fail 106
Name: test, dtype: int64
"""count_test = mpg['test'].value_counts()
count_test.plot.bar()
count_test.plot.bar(rot=0)
중첩 조건문 활용하기
1. 연비 등급 변수 만들기
2. 빈도표와 막대 그래프로 연비 등급 살펴보기
mpg['grade'] = np.where(mpg['total'] >= 30, 'A',
np.where(mpg['total'] >= 20, 'B', 'C'))
mpg.head()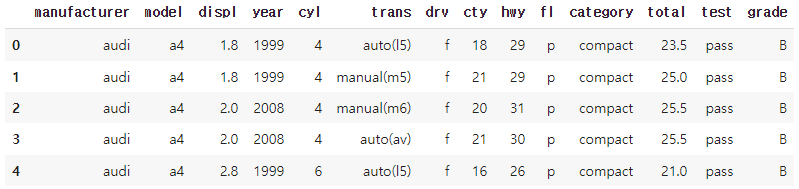
count_grade = mpg['grade'].value_counts()
count_grade
"""
B 118
C 106
A 10
Name: grade, dtype: int64
"""count_grade.plot.bar(rot=0)
알파벳 순으로 막대 정렬
count_grade = mpg['grade'].value_counts().sort_index()
count_grade
"""
A 10
B 118
C 106
Name: grade, dtype: int64
"""count_grade.plot.bar(rot=0)
메서드 체이닝(method chaining)
점을 이용해 메서드를 계속 이어서 작성하는 방법
변수에 여러 베서드를 순서대로 적용할 수 있으므로 출력 결과를 변수에 할당하고 다시 불러오는 작업을 반복하지 않아도 됨
df = mpg['grade']
df = df.value_counts()
df = df.sort_index()
df
"""
A 10
B 118
C 106
Name: grade, dtype: int64
"""df = mpg['grade'].value_counts().sort_index()
df
"""
A 10
B 118
C 106
Name: grade, dtype: int64
"""필요한 만큼 범주 만들기
np.where()를 중접하면 원하는 만큼 범주의 수를 늘릴 수 있음
mpg['grade2'] = np.where(mpg['total'] >= 30, 'A',
np.where(mpg['total'] >= 25, 'B',
np.where(mpg['total'] >= 20, 'C', 'D')))
mpg
목록에 해당하는 행으로 변수 만들기
mpg['size'] = np.where((mpg['category'] == 'compact') |
(mpg['category'] == 'subcompact') |
(mpg['category'] == '2seater'),
'small', 'large')
mpg['size'].value_counts()
"""
large 147
small 87
Name: size, dtype: int64
"""mpg['size'] = np.where(mpg['category'].isin(['compact', 'subcompact', '2seater']), 'small', 'large')
mpg['size'].value_counts()
"""
large 147
small 87
Name: size, dtype: int64
"""
※ 해당 내용은 <Do it! 파이썬 데이터 분석>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'데이터 분석 학습' 카테고리의 다른 글
| 6장 자유자재로 데이터 가공하기 (1) (0) | 2023.04.07 |
|---|---|
| 5장 데이터 분석 기초! - 데이터 파악하기, 다루기 쉽게 수정하기 (3) (0) | 2023.04.06 |
| 5장 데이터 분석 기초! - 데이터 파악하기, 다루기 쉽게 수정하기 (1) (0) | 2023.04.04 |
| 4장 데이터 프레임의 세계로 (2) (0) | 2023.04.03 |
| 4장 데이터 프레임의 세계로 (1) (0) | 2023.04.02 |



