반응형
정리하기
# 1. 패키지 로드
import pandas as pd
import numpy as np
# 2. 데이터 불러오기
mpg = pd.read_csv('mpg.csv')
# 3. 데이터 파악하기
mpg.head() # 데이터 앞부분
mpg.tail() # 데이터 뒷부분
mpg.shape # 행, 열 수
mpg.info() # 속성
mpg.describe() # 요약 통계량
# 4. 변수명 바꾸기
mpg = mpg.rename(columns = {'manufacturer' : 'company'})
# 5. 파생변수 만들기
mpg['total'] = (mpg['cty'] + mpg['hwy'])/2 # 변수 조합
mpg['test'] = np.where(mpg['total'] >= 20, 'pass', 'fail') # 조건문 활용
# 6. 빈도 확인하기
count_test = mpg['test'].value_counts() # 빈도표 만들기
count_test.plot.bar(rot = 0) # 빈도 막대 그래프 만들기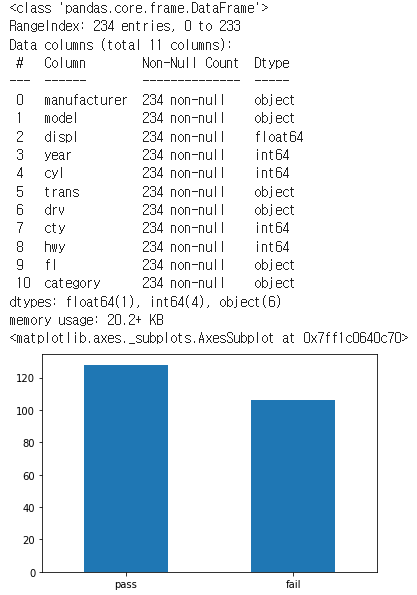
분석 도전
midwest.csv 를 이용하여 데이터 분석 문제 해결
Q1 midwest.csv를 불러와 데이터의 특징 파악
midwest = pd.read_csv('midwest.csv')
midwest.head()
midwest.tail()
midwest.info()
midwest.shape
midwest.describe()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 437 entries, 0 to 436
Data columns (total 28 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PID 437 non-null int64
1 county 437 non-null object
2 state 437 non-null object
3 area 437 non-null float64
4 poptotal 437 non-null int64
5 popdensity 437 non-null float64
6 popwhite 437 non-null int64
7 popblack 437 non-null int64
8 popamerindian 437 non-null int64
9 popasian 437 non-null int64
10 popother 437 non-null int64
11 percwhite 437 non-null float64
12 percblack 437 non-null float64
13 percamerindan 437 non-null float64
14 percasian 437 non-null float64
15 percother 437 non-null float64
16 popadults 437 non-null int64
17 perchsd 437 non-null float64
18 percollege 437 non-null float64
19 percprof 437 non-null float64
20 poppovertyknown 437 non-null int64
21 percpovertyknown 437 non-null float64
22 percbelowpoverty 437 non-null float64
23 percchildbelowpovert 437 non-null float64
24 percadultpoverty 437 non-null float64
25 percelderlypoverty 437 non-null float64
26 inmetro 437 non-null int64
27 category 437 non-null object
dtypes: float64(15), int64(10), object(3)
memory usage: 95.7+ KB
"""
Q2 poptotal(전체 인구) 변수를 total로, popasian(아시아 인구) 변수를 asian으로 수정
midwest = midwest.rename(columns = {'poptotal' : 'total'} )
midwest = midwest.rename(columns = {'popasian' : 'asian'})
midwest
Q3 total, asian 변수를 이용해 '전체 인구 대비 아시아 인구 백분율' 파생변수를 추가하고, 히스토그램을 만들어 분포를 살펴보기
midwest['ratio'] = midwest['asian'] / midwest['total'] * 100
midwest['ratio'].plot.hist()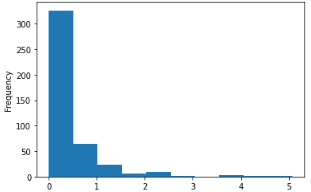
Q4 아시아 인구 백분율 전체 평균을 구하고, 평균을 초과하면 'large', 그외에는 'small'을 부여한 파생변수 만들기
midwest['ratio'].mean()
##출력: 0.4872461834357345midwest['group'] = np.where(midwest['ratio'] > 0.487, 'large', 'small')Q5 'large'와 'small'에 해당하는 지역이 얼마나 많은지 빈도표와 빈도 막대 그래프 만들기
count_test = midwest['group'].value_counts()
count_test
"""
small 318
large 119
Name: group, dtype: int64
"""count_test.plot.bar(rot=0)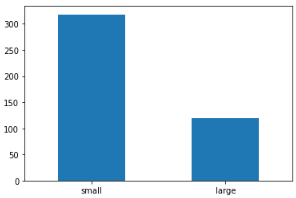
※ 해당 내용은 <Do it! 파이썬 데이터 분석>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'데이터 분석 학습' 카테고리의 다른 글
| 6장 자유자재로 데이터 가공하기 (2) (0) | 2023.04.08 |
|---|---|
| 6장 자유자재로 데이터 가공하기 (1) (0) | 2023.04.07 |
| 5장 데이터 분석 기초! - 데이터 파악하기, 다루기 쉽게 수정하기 (2) (0) | 2023.04.05 |
| 5장 데이터 분석 기초! - 데이터 파악하기, 다루기 쉽게 수정하기 (1) (0) | 2023.04.04 |
| 4장 데이터 프레임의 세계로 (2) (0) | 2023.04.03 |



