반응형
4.3 사이킷런으로 카운트 벡터 생성


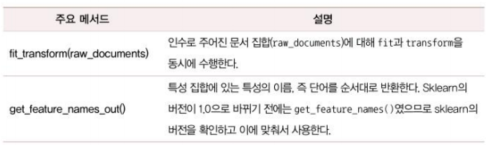
- CountVectorizer의 기능

# data 준비, movie_reviews.raw()를 사용하여 raw text를 추출
reviews = [movie_reviews.raw(fileid) for fileid in movie_reviews.fileids()]
from sklearn.feature_extraction.text import CountVectorizer
#cv = CountVectorizer() #모든 매개변수에 디폴트 값을 사용하는 경우
#앞에서 생성한 word_features를 이용하여 특성 집합을 지정하는 경우
cv = CountVectorizer(vocabulary=word_features)
#cv = CountVectorizer(max_features=1000) #특성 집합을 지정하지 않고 최대 특성의 수를 지정하는 경우
print(cv) #객체에 사용된 인수들을 확인
"""
CountVectorizer(vocabulary=['film', 'one', 'movie', 'like', 'even', 'time',
'good', 'story', 'would', 'much', 'also', 'get',
'character', 'two', 'well', 'first', 'characters',
'see', 'way', 'make', 'life', 'really', 'films',
'plot', 'little', 'people', 'could', 'bad', 'scene',
'never', ...])
"""reviews_cv = cv.fit_transform(reviews) #reviews를 이용하여 count vector를 학습하고, 변환
print(cv.get_feature_names_out()[:20]) # count vector에 사용된 feature 이름을 반환
print(word_features[:20]) # 비교를 위해 출력
"""
['film' 'one' 'movie' 'like' 'even' 'time' 'good' 'story' 'would' 'much'
'also' 'get' 'character' 'two' 'well' 'first' 'characters' 'see' 'way'
'make']
['film', 'one', 'movie', 'like', 'even', 'time', 'good', 'story', 'would', 'much', 'also', 'get', 'character', 'two', 'well', 'first', 'characters', 'see', 'way', 'make']
"""print('#type of count vectors:', type(reviews_cv))
print('#shape of count vectors:', reviews_cv.shape)
print('#sample of count vector:')
print(reviews_cv[0, :10])
"""
#type of count vectors: <class 'scipy.sparse._csr.csr_matrix'>
#shape of count vectors: (2000, 1000)
#sample of count vector:
(0, 0) 6
(0, 1) 3
(0, 2) 6
(0, 3) 3
(0, 4) 3
(0, 6) 2
(0, 8) 1
"""reviews_cv
"""
<2000x1000 sparse matrix of type '<class 'numpy.int64'>'
with 252984 stored elements in Compressed Sparse Row format>
"""print(feature_sets[0][:20]) #절 앞에서 직접 계산한 카운트 벡터
print(reviews_cv.toarray()[0, :20]) #변환된 결과의 첫째 feature set 중에서 앞 20개를 출력
"""
[5, 3, 6, 3, 3, 0, 2, 0, 1, 0, 1, 3, 1, 2, 1, 0, 1, 2, 3, 5]
[6 3 6 3 3 0 2 0 1 0 1 3 2 2 1 0 1 2 3 5]
"""for word, count in zip(cv.get_feature_names_out()[:20], reviews_cv[0].toarray()[0, :20]):
print(f'{word}:{count}', end=', ')
"""
film:6, one:3, movie:6, like:3, even:3, time:0, good:2, story:0, would:1, much:0, also:1, get:3, character:2, two:2, well:1, first:0, characters:1, see:2, way:3, make:5,
"""
※ 해당 내용은 <파이썬 텍스트 마이닝 완벽 가이드>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'텍스트 마이닝' 카테고리의 다른 글
| 카운트 기반의 문서 표현 (4) (0) | 2023.06.28 |
|---|---|
| 카운트 기반의 문서 표현 (3) (0) | 2023.06.27 |
| 카운트 기반의 문서 표현 (1) (0) | 2023.06.25 |
| 그래프와 워드 클라우드 (3) (0) | 2023.06.24 |
| 그래프와 워드 클라우드 (2) (0) | 2023.06.23 |



