반응형
4.5 카운트 벡터의 활용
- 문서로부터 특성을 추출하는 하나의 방법
- 이렇게 추출된 벡터는 머신러닝 기법을 적용하기 위한 입력으로 사용되어 문서 분류로부터 시작해 다양한 분야에 활용 가능
- 이전에 이 벡터는 문서 간의 유사도를 측정하는 데에 사용
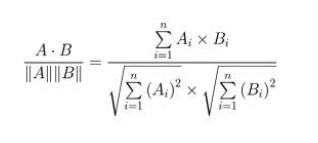
- 코사인 유사도: 두 벡터가 이루는 각도의 코사인값으로 정의되는 유사도

%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib as mpl
# 그래프에서 마이너스 폰트 깨지는 문제에 대한 대처
mpl.rcParams['axes.unicode_minus'] = False
import numpy as np
x = np.arange(0,2*np.pi,0.1) # start,stop,step
y = np.cos(x)
#print(x)
plt.plot(x, y)
plt.show()
from sklearn.metrics.pairwise import cosine_similarity
start = len(reviews[0]) // 2 #첫째 리뷰의 문자수를 확인하고 뒤 절반을 가져오기 위해 중심점을 찾음
source = reviews[0][-start:] #중심점으로부터 뒤 절반을 가져와서 비교할 문서를 생성
source_cv = cv.transform([source]) #코사인 유사도는 카운트 벡터에 대해 계산하므로 벡터로 변환
#transform은 반드시 리스트나 행렬 형태의 입력을 요구하므로 리스트로 만들어서 입력
print("#대상 특성 행렬의 크기:", source_cv.shape) #행렬의 크기를 확인, 문서가 하나이므로 (1, 1000)
sim_result = cosine_similarity(source_cv, reviews_cv) #변환된 count vector와 기존 값들과의 similarity 계산
print("#유사도 계산 행렬의 크기:", sim_result.shape)
print("#유사도 계산결과를 역순으로 정렬:", sorted(sim_result[0], reverse=True)[:10])
"""
#대상 특성 행렬의 크기: (1, 1000)
#유사도 계산 행렬의 크기: (1, 2000)
#유사도 계산결과를 역순으로 정렬: [0.8367205630128807, 0.43817531290756406, 0.4080451370075411, 0.40727044884302327, 0.4060219836225451, 0.3999621981759778, 0.39965783997760135, 0.39566661804603703, 0.3945302295079114, 0.3911637170821695]
"""import numpy as np
print('#가장 유사한 리뷰의 인덱스:', np.argmax(sim_result[0]))
## #가장 유사한 리뷰의 인덱스: 0print('#가장 유사한 리뷰부터 정렬한 인덱스:', (-sim_result[0]).argsort()[:10])
## #가장 유사한 리뷰부터 정렬한 인덱스: [ 0 1110 1570 687 628 112 1712 1393 524 1740]
※ 해당 내용은 <파이썬 텍스트 마이닝 완벽 가이드>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'텍스트 마이닝' 카테고리의 다른 글
| BOW 기반의 문서 분류 (1) (0) | 2023.06.30 |
|---|---|
| 카운트 기반의 문서 표현 (5) (0) | 2023.06.29 |
| 카운트 기반의 문서 표현 (3) (0) | 2023.06.27 |
| 카운트 기반의 문서 표현 (2) (0) | 2023.06.26 |
| 카운트 기반의 문서 표현 (1) (0) | 2023.06.25 |


