반응형
4.4 한국어 텍스트의 카운트 벡터 변환
4.4.1 데이터 다운로드
import pandas as pd
df = pd.read_csv('daum_movie_review.csv')
df.head(10)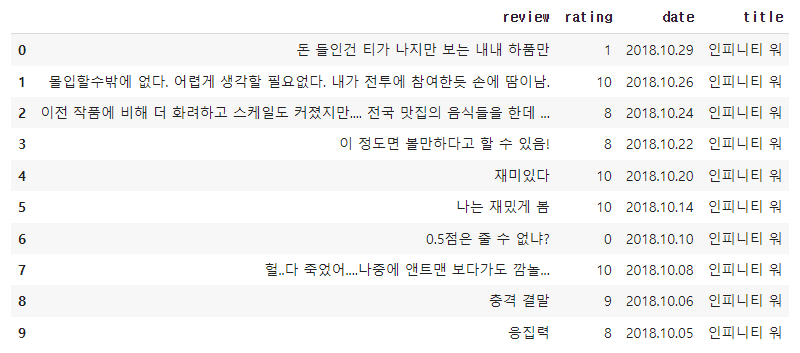
from sklearn.feature_extraction.text import CountVectorizer
daum_cv = CountVectorizer(max_features=1000)
daum_DTM = daum_cv.fit_transform(df.review)
print(daum_cv.get_feature_names_out()[:100])
"""
['10점' '18' '1987' '1도' '1점' '1점도' '2시간' '2시간이' '2편' '5점' '6점' '7점' '8점'
'cg' 'cg가' 'cg는' 'cg도' 'cg만' 'good' 'of' 'ㅋㅋ' 'ㅋㅋㅋ' 'ㅋㅋㅋㅋ' 'ㅎㅎ' 'ㅎㅎㅎ'
'ㅜㅜ' 'ㅠㅠ' 'ㅠㅠㅠ' 'ㅡㅡ' '가는' '가는줄' '가면' '가서' '가슴' '가슴아픈' '가슴이' '가장' '가족'
'가족과' '가족들과' '가족의' '가족이' '가지고' '간만에' '갈수록' '감독' '감독님' '감독은' '감독의' '감독이'
'감동' '감동과' '감동도' '감동은' '감동을' '감동이' '감동입니다' '감동적' '감동적이고' '감동적인' '감사드립니다'
'감사합니다' '감정이' '갑자기' '갔는데' '갔다가' '강철비' '강추' '강추합니다' '같고' '같네요' '같다' '같습니다'
'같아' '같아요' '같은' '같은데' '같음' '같이' '개연성' '개연성이' '개인적으로' '거의' '겁나' '것도' '것은'
'것을' '것이' '것이다' '겨울왕국' '결국' '결말' '결말이' '계속' '고맙습니다' '곤지암' '공포' '공포를'
'공포영화' '관객']
"""from konlpy.tag import Okt #konlpy에서 Twitter 형태소 분석기를 import
twitter_tag = Okt()
print('#전체 형태소 결과:', twitter_tag.morphs(df.review[1]))
print('#명사만 추출:', twitter_tag.nouns(df.review[1]))
print('#품사 태깅 결과', twitter_tag.pos(df.review[1]))
"""
#전체 형태소 결과: ['몰입', '할수밖에', '없다', '.', '어렵게', '생각', '할', '필요없다', '.', '내', '가', '전투', '에', '참여', '한', '듯', '손', '에', '땀', '이남', '.']
#명사만 추출: ['몰입', '생각', '내', '전투', '참여', '듯', '손', '땀', '이남']
#품사 태깅 결과 [('몰입', 'Noun'), ('할수밖에', 'Verb'), ('없다', 'Adjective'), ('.', 'Punctuation'), ('어렵게', 'Adjective'), ('생각', 'Noun'), ('할', 'Verb'), ('필요없다', 'Adjective'), ('.', 'Punctuation'), ('내', 'Noun'), ('가', 'Josa'), ('전투', 'Noun'), ('에', 'Josa'), ('참여', 'Noun'), ('한', 'Determiner'), ('듯', 'Noun'), ('손', 'Noun'), ('에', 'Josa'), ('땀', 'Noun'), ('이남', 'Noun'), ('.', 'Punctuation')]
"""def my_tokenizer(doc):
return [
token
for token, pos in twitter_tag.pos(doc)
if pos in ['Noun', 'Verb', 'Adjective']
]
print("나만의 토크나이저 결과:", my_tokenizer(df.review[1]))
## 나만의 토크나이저 결과: ['몰입', '할수밖에', '없다', '어렵게', '생각', '할', '필요없다', '내', '전투', '참여', '듯', '손', '땀', '이남']from sklearn.feature_extraction.text import CountVectorizer
#토크나이저와 특성의 최대개수를 지정
daum_cv = CountVectorizer(max_features=1000, tokenizer=my_tokenizer)
#명사만 추출하고 싶은 경우에는 tokenizer에 'twitter_tag.nouns'를 바로 지정해도 됨
daum_DTM = daum_cv.fit_transform(df.review) #review를 이용하여 count vector를 학습하고, 변환
print(daum_cv.get_feature_names_out()[:100]) # count vector에 사용된 feature 이름을 반환
"""
['가' '가는' '가는줄' '가면' '가서' '가슴' '가장' '가족' '가족영화' '가지' '가치' '각색' '간' '간다'
'간만' '갈' '갈수록' '감' '감독' '감동' '감사' '감사합니다' '감상' '감성' '감정' '감탄' '갑자기' '갔는데'
'갔다' '갔다가' '강' '강철' '강추' '같고' '같네요' '같다' '같습니다' '같아' '같아요' '같은' '같은데'
'같음' '개' '개그' '개봉' '개연' '개인' '거' '거기' '거리' '거의' '걱정' '건' '건가' '건지' '걸'
'겁니다' '것' '게' '겨울왕국' '결론' '결말' '경찰' '경험' '계속' '고' '고맙습니다' '고민' '고생' '곤지암'
'곳' '공감' '공포' '공포영화' '과' '과거' '관' '관객' '관객수' '관람' '광주' '괜찮은' '교훈' '구성'
'국내' '국민' '군인' '군함도' '굿' '권선' '귀신' '그' '그것' '그게' '그날' '그냥' '그닥' '그대로'
'그때' '그래픽']
"""print(repr(daum_DTM))
print(110800/(14725*1000))
"""
<14725x1000 sparse matrix of type '<class 'numpy.int64'>'
with 110800 stored elements in Compressed Sparse Row format>
0.007524617996604414
"""for word, count in zip(daum_cv.get_feature_names_out(), daum_DTM[1].toarray()[0]):
if count > 0:
print(word, ':', count, end=', ')
## 내 : 1, 듯 : 1, 몰입 : 1, 생각 : 1, 손 : 1, 없다 : 1, 할 : 1,
※ 해당 내용은 <파이썬 텍스트 마이닝 완벽 가이드>의 내용을 토대로 학습하며 정리한 내용입니다.
반응형
'텍스트 마이닝' 카테고리의 다른 글
| 카운트 기반의 문서 표현 (5) (0) | 2023.06.29 |
|---|---|
| 카운트 기반의 문서 표현 (4) (0) | 2023.06.28 |
| 카운트 기반의 문서 표현 (2) (0) | 2023.06.26 |
| 카운트 기반의 문서 표현 (1) (0) | 2023.06.25 |
| 그래프와 워드 클라우드 (3) (0) | 2023.06.24 |



